 Exactly 7 years ago, a team of research scientists at Google Research and Google Brain released a paper titled “Attention is all you need”. In this paper, they proposed a “simple network architecture” called the “Transformer”. This became the pivotal and legendary architecture which now powers every large language model on our planet. Such is the nature of technology. One research paper is enough, to change the world. What kind of advancements are waiting for us in the future? Will there be another paper like this? More importantly, can we afford to miss it? This is why we come to you weekly with all the latest updates in the world of technology, right from the edge of tomorrow. Let’s dive into what happened this week.
Exactly 7 years ago, a team of research scientists at Google Research and Google Brain released a paper titled “Attention is all you need”. In this paper, they proposed a “simple network architecture” called the “Transformer”. This became the pivotal and legendary architecture which now powers every large language model on our planet. Such is the nature of technology. One research paper is enough, to change the world. What kind of advancements are waiting for us in the future? Will there be another paper like this? More importantly, can we afford to miss it? This is why we come to you weekly with all the latest updates in the world of technology, right from the edge of tomorrow. Let’s dive into what happened this week.
This article is brought to you in partnership with Truetalks Community by Truecaller, a dynamic, interactive network that enhances communication safety and efficiency. https://community.truecaller.com
 Pixtral 12B v0.1 is Mistral’s first Multi-Modal Open Source LLM
Pixtral 12B v0.1 is Mistral’s first Multi-Modal Open Source LLM
Mistral is a French AI start-up known for its highly popular series of LLMs, mainly because they are open-source. Anyone could download and start using it, and it was made so easy to download via Torrents that, it gained a lot of fame among the open source and LLM enthusiasts alike. A while back, it was Meta, which launched a huge open source model – Llama 3 with nearly 400 billion parameters. Competing against it is Mistral, which has come up with its first Multi-modal LLM called “Pixtral v0.1” which is a comparatively lighter model with 12 billion parameters. In LLM-speak, the number of parameters determines the complexity of the model, as to what kind of fine-tuning has been done on it. In the case of Pixtral, it is clear that it is based on the already fine-tuned Nemo-12B model that Mistral allows for download. Since the news is hot off the press, many of the GPU-powered enthusiasts are still downloading the 28GB torrent and the developers are yet to host it on capable servers, so the jury is still out on Pixtral’s capabilities but this much is clear – the model is capable to not only understanding text, but understanding images as well. Which means, it is only a matter of time, until someone makes it generate images as well. For the geeks, the specifications are as follows –
1. Text backbone: Mistral Nemo 12B 2. Vision Adapter: 400M 3. Uses GeLU (for vision adapter) & 2D RoPE (for vision encoder) 4. Larger vocabulary – 131,072 5. Three new special tokens – `img`, `img_break`, `img_end` 6. Image size: 1024 x 1024 pixels 7. Patch size: 16 x 16 pixels 8. Tokenizer support in mistral_common
We will update you with more details next week, once the developers and enthusiasts start benchmarking this new piece of code. Surely, the LLM world will be happy to have more competition!
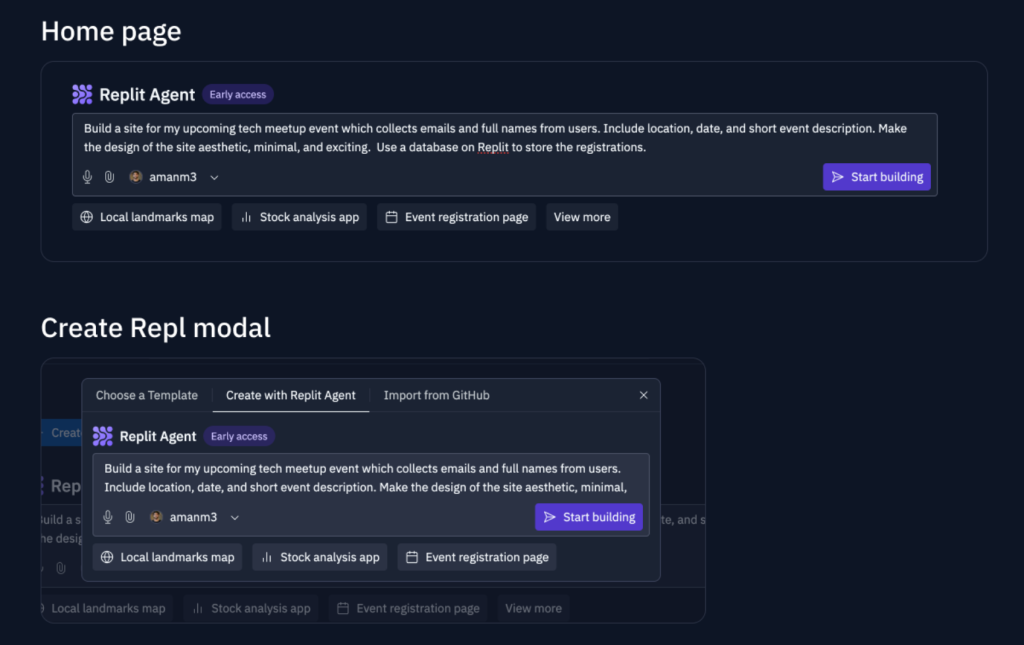 Develop apps with zero coding knowledge with “Replit Agent”
Develop apps with zero coding knowledge with “Replit Agent”
While “Cursor AI” was all the buzz some weeks back, Replit, the online IDE with support for more than 50 programming languages, launched its own AI coding assistant called “Replit Agent“. Announced by CEO Amjad Masad, the Agent, which is already available as an early access feature for all coders, will help in every step of the way, to build any kind of program from scratch. The beauty is, thanks to the power of LLM, it makes coding so simple that, all you need to do, write prompts in natural language in a text box. The coder can ask anything they want, and the agent would just do it. In a demo video, Amjad asks the agent to “Make an app with local landmarks” in which he wants to add a search bar. Once the prompt is typed, there is a live update of what the Agent is doing in real time, as it writes code, uses the same repositories that a developer usually uses. Nothing is obscured, because whatever the agent does, is fully visible to the coder in real-time. In the “chat window”, the coder can give the Agent the feedback, as it makes changes in real-time, fulfilling all the requirements. Basically the Replit Agent is doing what a developer would be doing, the same actions, imitated to produce a much faster workflow, or even goes to the extent where the developer wouldn’t need any coding knowledge, and just “ask” the Agent to develop a program for them. Such a wild feature is now actually a reality in Replit, which is already well known amongst developers and coding enthusiasts. “Any time you have an idea, it doesn’t have to be a fleeting idea, you can just make it happen, and the code is all yours, it’s there.” says Amjad in his intro video, detailing his inspiration behind this feature. In just 2 mins, in the demo video, he was able to add a complex “search” feature in his “ladmarks near me” app and deploys it to production. Ever heard of such a rapid time-to-market scenario? Well, that’s what Replit Agent is for, and it’s already getting some rave reviews from developers and enthusiasts who want to develop prototypes in an instant. Have you tried “Cursor” or “Replit Agent” yet?
Hailuo “Minimax” AI – Hollywood production without a crew
Once again, the Chinese have changed the game. A month back, “Kling AI” made a lot of waves in the GenAI video space, as it became an extremely formidable competitor to USA-based LLMs like LumaLabs and Runway. Now, it’s the turn of “Hailuo – Minimax” to completely dominate the GenAI ecosystem this week. What’s so special? Well, first of all, it’s an entirely “Text to Video” model, in which, you type just the prompts, and with no kind of image guidance, the video will be generated. And the kind of videos it is generating, is easily top-tier in the current scenario, mainly because there is no artificial “slow motion” effect which is currently the pitfall of almost all the other video models. Check out their demo video for the kind of results that are possible with this video model –
Since it is free to try, a lot of users have tried their hand with this model and are sharing some insane results. Like this thread here, the videos generated by this model seem to have a particular cinematic feel to it, suggesting that a lot of films have been used to train this model. In another post, the output is just stunning, to say the least. The colors, the movement, everything, when prompted right, seems to be right on track. Imagine creating your own movie, with this AI model, and you need nothing but a screenplay in your hands. This is exactly what the Hailuo-Minimax video model is going for. And this is just the beginning. After more updates, we are sure, this will one of the best video models to have come out of China. Hot on the heels of this update, we also have “Adobe Firefly” which just came out with its own video model, with safe “copyright-free” generation. We will have more of this next week.
 AI that can do lip-reading and make captions
AI that can do lip-reading and make captions
Symphonic Labs is an AI startup based in San Francisco and Waterloo (Canada), which works on tools for multi-modal speech understanding. They have released a new tool on a website that has a name “readtheirlips” which is pretty self-explanatory. It’s a very simple yet extremely powerful tool, in which, all you need to do is, upload a video which you would want to decipher, and it will transcribe the captions, not based on convoluted audio processing algorithms, rather, it will use super-complex vision algorithms to read lips using motion-capture-like tech. Let’s imagine a scenario where you have footage that is taken from afar, or taken with a disadvantage of having distorted audio. It’s nearly impossible to make captions for such videos, as many subtitling specialists and experts know and have faced these situations in many documentaries. Well, this is the exact problem that the solution from Symphonic Labs tends to solve, with lip-reading. Taking advantage of a well-trained model that is specifically tutored on motion-data of faces, the tool is able to accurately figure out the movements of the eyes, the cheek bones and the mouth to reconstruct a perfect caption for that particular video sequence. Of course, a lot of responses were of concern on artificial intelligence entering the domain of surveillance, in which an all-powerful state will be able to monitor the speech and expressions of all its citizens. But guess what masks are for? Well, not all tools require such a scrutiny but when it comes to latest technology, we always face detractors who would like to delay it as much as possible and maintain a status quo. However, history has taught us that technology advancements are inevitable and such a lip-reading solution might be of widespread use in forensics of the future investigative agencies.
A Walking Table?
 In this week’s robotics update is a walking table called “Carpentopod” by designer Giliam De Carpentier. Yes, it’s a real thing, and a great personal project of Giliam, which is detailed in his blog. According to the designer, this pet project had been in the works for many years as something way back in 2008 when he wanted to generate various walking mechanisms in software. Since then, he has been gaining electronic skills and more working skills on wood design. The result, is a wireless walking wooden coffee table, that can be controlled using a joystick. It features a very interesting leg linkage mechanism in which, the table is able to actually move its legs. A total of 6 legs on each side were actually designed and solved in C++ programming, with a kinematics solver and the algorithm was refined by making the legs compete with each other, through various parameters. Both six-legged sections, driven by motors, use simple electronics. “Is it honestly very useful? Maybe not. But is it fun to make it bring me a drink? Very much so.” claims Giliam who got flooded with requests to buy one. However, he is not making them on demand, but has open sourced his designs on his blog and documented the entire process of making it. Such a cool indie project that has been in the works for 16 years, is a sigh to behold, indeed.
In this week’s robotics update is a walking table called “Carpentopod” by designer Giliam De Carpentier. Yes, it’s a real thing, and a great personal project of Giliam, which is detailed in his blog. According to the designer, this pet project had been in the works for many years as something way back in 2008 when he wanted to generate various walking mechanisms in software. Since then, he has been gaining electronic skills and more working skills on wood design. The result, is a wireless walking wooden coffee table, that can be controlled using a joystick. It features a very interesting leg linkage mechanism in which, the table is able to actually move its legs. A total of 6 legs on each side were actually designed and solved in C++ programming, with a kinematics solver and the algorithm was refined by making the legs compete with each other, through various parameters. Both six-legged sections, driven by motors, use simple electronics. “Is it honestly very useful? Maybe not. But is it fun to make it bring me a drink? Very much so.” claims Giliam who got flooded with requests to buy one. However, he is not making them on demand, but has open sourced his designs on his blog and documented the entire process of making it. Such a cool indie project that has been in the works for 16 years, is a sigh to behold, indeed.
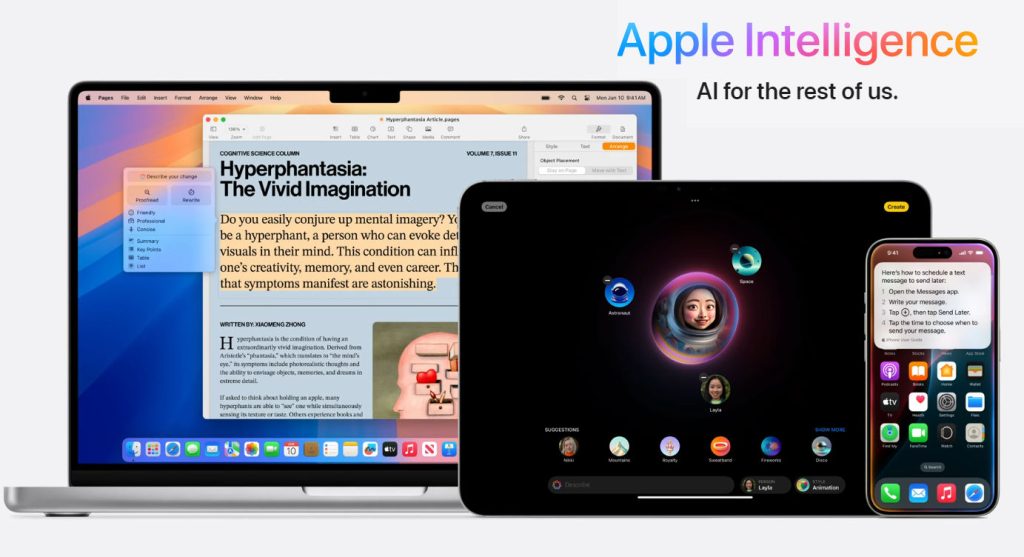 Apple Intelligence gains Vision
Apple Intelligence gains Vision

Finally, this is the much celebrated update of the week, Apple Intelligence has gained new skills in Vision processing. That means, Apple’s own implementation of LLMs has gone multi-modal. Apart from integrations with ChatGPT, Apple had introduced its own “private on-device models” for a more personalized experience of AI and called it “Apple Intelligence”. It’s an extension of Siri, which is gaining a lot of new capabilities. With Visual Intelligence, the new iPhone camera control button acts as a trigger point for just pointing at anything using the camera and asking Siri for information about it. One of the funnier demos that Apple showcased was of a iPhone user walking up to a dog, and taking a photo, then proceeds to ask Siri what kind of dog it is, for which Siri will answer. The multi modal capabilities also expand to notifications and emails, as summaries will be generated in the notifications panel cards where previous only truncated texts were visible. Another feature that Apple added is the ability to search through tons of videos and photos to figure out specific moments through natural language understanding. This means that Apple Intelligence now has the ability to fully understand text, audio, photos and video, making it truly powerful in the era of on-device LLMs. Aiding it is the newly spruced up A18 Pro chipset, which has more NPUs than the previous generations. With this update, Apple is moving into the AI era at full speed, with Google playing catch-up with Gemini’s implementations. It will be very interesting to see how Google responds and more importantly, how pure-play AI companies like OpenAI will take it.
This concludes the wrap-up of all the latest from the world of technology this week, from Team FoneArena. There is always a lot more happening in this dynamic, so don’t forget to come back next week!