 A new month in the world of technology begins with our fifth week, traversing stories at the edge of tomorrow. A long awaited release from OpenAI has, once again, shaken up the LLM sphere. Fei Fei Li, the godmother of AI has announced the existence of “World Labs”. A lot of people are surprised that Google is actually shipping a lot of good stuff, and so have much smaller companies like Runway, Perplexity, Suno and Krea. In fact, even Adobe managed to bring out a video model. A world-model for robots, new AR glasses and a really interesting haptics accessory find places in our report this week from Team FoneArena. Dive in for a sneak peek into the future.
A new month in the world of technology begins with our fifth week, traversing stories at the edge of tomorrow. A long awaited release from OpenAI has, once again, shaken up the LLM sphere. Fei Fei Li, the godmother of AI has announced the existence of “World Labs”. A lot of people are surprised that Google is actually shipping a lot of good stuff, and so have much smaller companies like Runway, Perplexity, Suno and Krea. In fact, even Adobe managed to bring out a video model. A world-model for robots, new AR glasses and a really interesting haptics accessory find places in our report this week from Team FoneArena. Dive in for a sneak peek into the future.
This article is brought to you in partnership with Truetalks Community by Truecaller, a dynamic, interactive network that enhances communication safety and efficiency. https://community.truecaller.com
Adobe Firefly video model comes alive
 Sometimes, you cannot write off industry stalwarts like Adobe who have just released their brand-new Firefly video model. One more feather in the cap for the company that makes pro tools for creative professionals. Following the launch of Firefly in 2023, a year later, Adobe has promised to roll out this video model that they promise “is not trained on copyrighted material”. Moreover, Firefly video model will be directly integrated in to Premiere Pro, much like how the imaging features were directly integrated in Photoshop. Much like the newer video models like KlingAI and Hailuo Minimax, Adobe will let us do text-to-video and have showcased in their blog, some really fantastic results.
Sometimes, you cannot write off industry stalwarts like Adobe who have just released their brand-new Firefly video model. One more feather in the cap for the company that makes pro tools for creative professionals. Following the launch of Firefly in 2023, a year later, Adobe has promised to roll out this video model that they promise “is not trained on copyrighted material”. Moreover, Firefly video model will be directly integrated in to Premiere Pro, much like how the imaging features were directly integrated in Photoshop. Much like the newer video models like KlingAI and Hailuo Minimax, Adobe will let us do text-to-video and have showcased in their blog, some really fantastic results.
For now, the Firefly video model is in limited access. It’s available for a very few, and if we want to try it, we must join the waitlist. Pretty soon, Creative Cloud users might get access in a wider way, but for free users, using just the Adobe Express solution might just have to wait a bit longer. The standout feature of Adobe’s video model, is undoubtedly, the integration into premiere pro, where the model will be used to perform some editing tricks, like rotoscoping something in or out of the frames, “Generative Extend” in which existing shots can be extended for longer times. There will be tools to generate and add motion graphics effects, and since it is trained on stock footage, it will be able to generate a lot of world footage with high quality results, as claimed by Adobe. The model will also have the ability to execute custom camera controls and movements, which are necessary for professional users. Adobe jumping into the video model bandwagon creates additional value to the ecosystem, no doubt. But at the same time, the field is still wide open for incumbents of any size to make their mark.
RunwayML Gen3 Alpha video to video update is here
 If there’s one company that is shipping features without a break, it has got to be RunwayML, the well known GenAI solution, which recently made a lot of advancement in their generative video models with Gen3. The latest “alpha” version in the paid tier includes a new feature, and that is having the ability to use GenAI to transform entire videos. Imagine applying a filter to a video and it changes the entire story itself. For example, you might stand in front of the camera, wearing something you would wear at home, and holding a cardboard gun, and the video to video GenAI model could transform you into a soldier who is armed, guarding a space-ship with a suit and what not, with the entire environment changed to suit the scene. Such kind of magical transformation, with consistency, is possible with the video to video model in Gen3 Alpha. Runway has shared a lot of examples, in their thread on X, which can very well demonstrate the kind of power that GenAI will have in the field of video editing.
If there’s one company that is shipping features without a break, it has got to be RunwayML, the well known GenAI solution, which recently made a lot of advancement in their generative video models with Gen3. The latest “alpha” version in the paid tier includes a new feature, and that is having the ability to use GenAI to transform entire videos. Imagine applying a filter to a video and it changes the entire story itself. For example, you might stand in front of the camera, wearing something you would wear at home, and holding a cardboard gun, and the video to video GenAI model could transform you into a soldier who is armed, guarding a space-ship with a suit and what not, with the entire environment changed to suit the scene. Such kind of magical transformation, with consistency, is possible with the video to video model in Gen3 Alpha. Runway has shared a lot of examples, in their thread on X, which can very well demonstrate the kind of power that GenAI will have in the field of video editing.
World Labs is here, to solve Spatial Intelligence
 Fei Fei Li, considered to be one of the top-most thinkers in the field of artificial intelligence of this era, has announced the existence of a company she helped co-found called “World Labs” which exists solely to solve the problem of “Spatial Intelligence”. The most important difference between World Labs and other companies will be that of the fundamental nature of data on what the models are trained on. “Large Language Models” deal with the interaction of people with each other, meanwhile the “Large World Models” will deal with the interaction of people with objects and places.
Fei Fei Li, considered to be one of the top-most thinkers in the field of artificial intelligence of this era, has announced the existence of a company she helped co-found called “World Labs” which exists solely to solve the problem of “Spatial Intelligence”. The most important difference between World Labs and other companies will be that of the fundamental nature of data on what the models are trained on. “Large Language Models” deal with the interaction of people with each other, meanwhile the “Large World Models” will deal with the interaction of people with objects and places.
we need spatially intelligent AI that can model the world and reason about objects, places, and interactions in 3D space and time
World Labs will develop spatially intelligent Large World Models (LWMs) that can understand and reason about the 3D world from images and other modalities. Over time, they expect to train increasingly powerful models with broader capabilities that can be applied in a variety of domains, working alongside people. World Labs was founded by visionary AI pioneer Fei-Fei Li along with Justin Johnson, Christoph Lassner, and Ben Mildenhall; each a world-renowned technologist in computer vision and graphics.
OpenAI’s new O1 series of models will “think” before responding
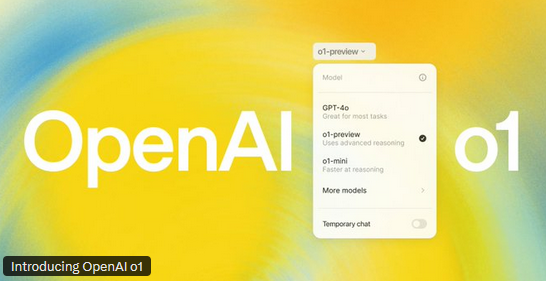 Finally, the time has come for us to know what “Strawberry” is. The strawberry problem of finding how many “R”s does the world strawberry have, was an amusing way to check whether the AI model is able to “think” and answer. Most of the times, all the models were wrong and in each answer, predicted the wrong number always. This has now been solved for, now there are models that can “think” before they respond. A new series of models have been released by OpenAI, which released as an announcement on their blog.
Finally, the time has come for us to know what “Strawberry” is. The strawberry problem of finding how many “R”s does the world strawberry have, was an amusing way to check whether the AI model is able to “think” and answer. Most of the times, all the models were wrong and in each answer, predicted the wrong number always. This has now been solved for, now there are models that can “think” before they respond. A new series of models have been released by OpenAI, which released as an announcement on their blog.
We trained these models to spend more time thinking through problems before they respond, much like a person would. Through training, they learn to refine their thinking process, try different strategies, and recognize their mistakes.
With more time for reasoning and evaluation, these larger and more power-consuming state-of-the-art models will be able to solve some of the most complex and tough problems of the day and, sometimes, even excel at it. These new o-1 series of models were supposedly great with math and physics problems at scale. For a comparison, in a qualifying exam for the International Mathematics Olympiad (IMO), previously released GPT-4o correctly solved only 13% of problems, while the o-1 reasoning model scored 83%. Their coding abilities were evaluated in contests and reached the 89th percentile in Codeforces competitions. So, these new models will be able to code as well, and in fact, apply reasoning and depth to any and every request from the user, because that is how these models are trained. The o-1 mini is a smaller model particularly good at coding skills and will be 80% lower-cost compared to the o-1 preview. Currently, the Plus and Pro users of ChatGPT will be able to test these models, with a rate limit of 20 tokens per minute. A lot of people say that’s very little to work with, and that they keep hitting the rate limits. This is just evidence that all the new AI models will require a substantial amount of energy to produce results. In a thread, a lot of the capabilities of the o-1 series of models are explained – it can develop a simple video game from a prompt, it can solve quantum physics problems, solve complex logic puzzles, work on genetics and so on.
NotebookLM – Make a conversational podcast from your notes
 Google’s “Virtual Research Assistant” NotebookLM, which can take in your own sources and answer questions from those sources, has got a new feature drop. This tool, which was initially aimed at helping research scientists go through hundreds of research papers and parse information inside it has something called “Audio Overview” now. It takes summarizing of your sources one step ahead by creating a whole podcast episode, discussed like a conversation between two AI hosts.
Google’s “Virtual Research Assistant” NotebookLM, which can take in your own sources and answer questions from those sources, has got a new feature drop. This tool, which was initially aimed at helping research scientists go through hundreds of research papers and parse information inside it has something called “Audio Overview” now. It takes summarizing of your sources one step ahead by creating a whole podcast episode, discussed like a conversation between two AI hosts.
Today, we’re introducing Audio Overview, a new way to turn your documents into engaging audio discussions. With one click, two AI hosts start up a lively “deep dive” discussion based on your sources. They summarize your material, make connections between topics, and banter back and forth. You can even download the conversation and take it on the go.
According to the quote above, it is clear that the feature is a boon for content creators who are focused on the writing instead of the audio production. Some examples that were shared on Twitter were raving about the realism that was offered by the AI hosts. Obviously, there will be issues when it comes to accuracy, but since this is a new feature, we can expect overhauls to the next versions. Articles, PDFs, Website, or just plain text, can be given as input and a completely AI-driven podcast can be generated.
1x reveals its own “World Model”
 After LLMs, LWMs are currently in vogue. The robotics startup from San Francisco, 1x tech, which we covered already as the one who introduced Neo, the humanoid robot a couple of weeks back, has announced that it is building its own World Model. Similar to world models for autonomous cars, the 1X humanoids will be training in a simulated world with regular obstacles and challenges that are meant to make the humanoid learn its environment.
After LLMs, LWMs are currently in vogue. The robotics startup from San Francisco, 1x tech, which we covered already as the one who introduced Neo, the humanoid robot a couple of weeks back, has announced that it is building its own World Model. Similar to world models for autonomous cars, the 1X humanoids will be training in a simulated world with regular obstacles and challenges that are meant to make the humanoid learn its environment.
Over the last year, we’ve gathered thousands of hours of data on EVE humanoids doing diverse mobile manipulation tasks in homes and offices and interacting with people. We combined the video and action data to train a world model that can anticipate future video from observations and actions.
With their earlier bot called EVE, which came before the Neo, they have been gathering a lot of visual data of the usual manipulations that the robot performed around its environments and fed that into the model as training data. This means, they have their own data set of interactions, which they will leverage to create repeated actions and interactions in the world model. Simple actions such as opening a door, avoiding obstacles, folding t-shirts, picking and dropping items, all of it when trained on visual and interactive data, produces much better results, according to their blog.
Perplexity, Suno and Krea AI get new features
 This is a quick round-up of the latest feature drops in some of the popular AI tools that are being used by a lot of people. Perplexity is a solid search and explore driven tool which aims to replace the likes of Google with smarter LLM-based technology. They have announced a new “Discover” page where it can be completely customized according to your interests, in your own language, with a feed that can be scrolled infinitely, as cards stacked on top of each other. This feature is available right now.
This is a quick round-up of the latest feature drops in some of the popular AI tools that are being used by a lot of people. Perplexity is a solid search and explore driven tool which aims to replace the likes of Google with smarter LLM-based technology. They have announced a new “Discover” page where it can be completely customized according to your interests, in your own language, with a feed that can be scrolled infinitely, as cards stacked on top of each other. This feature is available right now.
 Suno, the crazy music production model that has been live for quite a while now, can now create song covers, which means, you can just sing a vocal sample, and then using just a prompt, it will add background music to your modified in-tune voice. This update is also live right now.
Suno, the crazy music production model that has been live for quite a while now, can now create song covers, which means, you can just sing a vocal sample, and then using just a prompt, it will add background music to your modified in-tune voice. This update is also live right now.
 Krea AI is a GenAI imaging solution which is very well known for its realtime application of generative images. It has added the very popular and high quality “Flux” open source model to its catalog, with realtime generation possible. For creators who use these tools regularly, these are updates that can’t be missed.
Krea AI is a GenAI imaging solution which is very well known for its realtime application of generative images. It has added the very popular and high quality “Flux” open source model to its catalog, with realtime generation possible. For creators who use these tools regularly, these are updates that can’t be missed.
Snapchat’s new Spectacles with AR
 Snapchat, the uber popular social network of short video content, rose to popularity on the back of AR stickers and 3D assets that were overlaid on the real world by millions of its users. To take advantage of this phenomenon, they had launched their first hardware product, the “Spectacles” earlier, which were initially considered as a video camera that can be worn on the face, to shoot interesting point of view footage, but this time, they have taken things further with the 2024 version of the Spectacles which have a waveguide display that can radically improve visibility and have a the ability to display 3D renderings with enough frames per second that it becomes usable in 3D space. Powered by 2x Snapdragon XR chips, one on each side, the Spectacles run a brand new operating system “SnapOS” to power the 3D overlays and UI elements that drive the entire experience. There are a lot of developers who are onboard this program, in which, all of them were given a task to develop a “shared experience” as the main theme.
Snapchat, the uber popular social network of short video content, rose to popularity on the back of AR stickers and 3D assets that were overlaid on the real world by millions of its users. To take advantage of this phenomenon, they had launched their first hardware product, the “Spectacles” earlier, which were initially considered as a video camera that can be worn on the face, to shoot interesting point of view footage, but this time, they have taken things further with the 2024 version of the Spectacles which have a waveguide display that can radically improve visibility and have a the ability to display 3D renderings with enough frames per second that it becomes usable in 3D space. Powered by 2x Snapdragon XR chips, one on each side, the Spectacles run a brand new operating system “SnapOS” to power the 3D overlays and UI elements that drive the entire experience. There are a lot of developers who are onboard this program, in which, all of them were given a task to develop a “shared experience” as the main theme.
Spectacles are standalone, see-through AR glasses powered by Snap OS. Use My AI, launch immersive Lenses, and extend your Snapchat experience into three dimensions.



When it comes to technical specs, the 45-minute battery life of the spectacles, the design and generally, the whole utility of the product was heavily questioned on social media where it garnered only lukewarm attention. But really, the display is a breakthough, because for the first time, in such a small form factor, there is a product with a “See-through stereo display with optical waveguides and Liquid crystal on silicon (LCoS) miniature projectors”. If this is possible in 2024, imagine what all is possible at a later stage when such designs can be even further miniaturized.
Haptic Gloves to feel objects in VR
 A new product, which promises to address an extremely forward looking use case in the world of virtual reality goes by the name “SenseGlove Nova 2” which is a glove, with “Active Contact Feedback” which is basically haptic feedback for feeling objects which are completely unreal, in your hands, during a VR experience. Imagine if you touch the grass in a virtual world and actually feel it in your hands as invisible vibrations that create the same feel of touch. The most amazing feature is being able to “grasp” things which means, there will be opposing forces working on your hand when you “hold” an object in VR. In fact, it goes one step further with pressure sensitivity, in that which the softness or hardness of objects can be felt. And then there is always the haptics, which give the tactile feedback of objects. When you add finger level tracking to this, it makes sense why the pricing is so high for this product. The amount of sensors and tracking data, and to process it, will be extremely tough for any company to work on, at the current stage. But SenseGlove have done it, ahead of many others, and it shows. Here’s a video to show how it works and all that goes along with it
A new product, which promises to address an extremely forward looking use case in the world of virtual reality goes by the name “SenseGlove Nova 2” which is a glove, with “Active Contact Feedback” which is basically haptic feedback for feeling objects which are completely unreal, in your hands, during a VR experience. Imagine if you touch the grass in a virtual world and actually feel it in your hands as invisible vibrations that create the same feel of touch. The most amazing feature is being able to “grasp” things which means, there will be opposing forces working on your hand when you “hold” an object in VR. In fact, it goes one step further with pressure sensitivity, in that which the softness or hardness of objects can be felt. And then there is always the haptics, which give the tactile feedback of objects. When you add finger level tracking to this, it makes sense why the pricing is so high for this product. The amount of sensors and tracking data, and to process it, will be extremely tough for any company to work on, at the current stage. But SenseGlove have done it, ahead of many others, and it shows. Here’s a video to show how it works and all that goes along with it
And that concludes the list of news that we had wanted to share with you this week. Even while typing this article out, there are new updates coming in, for this is the world of technology, it never sleeps. So, make sure to come back next week, for the latest and juiciest updates from the edge of tomorrow.